未来的可能 – 爱情
坐飞机回成都的时候,看到篇文章不错。深有感触。
到成都的时候和朋友聊天吃饭,又加深了一番。
在这个危险的年代,颇有一群人在寻找中等待,在等待中寻找。遇到个漂亮妹纸就心慌错乱,目测到条件不错的公的就想扑倒,看到有房有车的就想偷户口本。
这其中,有多少的大同小异,又有多少的不可替代,怕是谁也不知道。前一秒的海誓山盟,后一秒的背道而驰。
幸福如饮水,冷暖自知。但谁又能读懂你的真心,和你一起共同走过崎岖的岁月。
对于“唯一”的含义,很多人究其一生也都无法理解。
小时候,觉得能玩在一起,就是比较喜欢的人了。
长大点,觉得能陪你聊天,娱乐,能相互鼓励,就算遇到对的人了。
再后来的定义就更规矩了,能买房买车能生娃能育儿能伴老。终了一生。
春夏秋冬,是岁月把生活过小了,还是时间把我们消逝了?
时常和友人说,现在工作的时间除外,那就是你和另一半的时间,算上周末,加起来的时间还没和同事在一起的多,那你到底是需要多在乎,才能接受那唯一的到来。
一起开始的未必会走到结束,一开始看好的未必会开始。很多时候我在想,究竟我们喜欢的是一个人本身,还是喜欢一种预期,一种前景,一种对未来生活状态的可能? 上辈子答应这辈子也要找到你的那位变了容貌,改了性格,易了妆容,还能续否?
“他拒绝我,我会喜欢她;他不听我电话,我还是喜欢她;他和别人结婚,我还是喜欢他;他死了,我还是喜欢她”的故事,就好似南柯一梦,浮生无常,连现在的电影都不愿意再拍了。
年少时那些孱弱的美境,敌不过这坚硬的世界。我们慢慢学会将就,学会隐忍,学会放弃。多年后,我们逐渐懂得生命的时光越走越短,能真正进入你心中的人越来越少,曾经深根蒂固的情感,也会慢慢剥离根系,从你的生活轨迹中消逝。有一天,你会开始习惯告别,习惯真的再也不见。
地老天荒是需要多勇敢?多舍得?呵呵 谁也不知道 。当盖茨比坠入泳池的时候,天真的梦想也只能淹没在一片迷惘中,消散。
golang go安装环境和编辑器
一、下载和安装
非常遗憾,go的官网是放在了gae上,国内不能访问。
可以直接进他的项目主页【http://code.google.com/p/go/】
里面有各种版本的源包下载。
以windows的1.1.1版举例。
http://code.google.com/p/go/downloads/list
下回来后解压到一个位置(最好不要带空格的路径)
比如我这里是D:\go
二、配置环境变量
接下来要配置环境变量。
需要两个GOROOT和GOPATH
windows里面打开
计算属性-高级系统属性-高级-环境变量
如下图加入

GOROOT设置为你的go安装路径
GOPATH设置到你的go可执行文件的路径 一般是GOROOT/bin
linux下面简单用命令设下
export PATH=$PATH:/opt/go/
export GOROOT=/opt/go/
export GOPATH=$GOROOT/bin
即可
三、关于IDE和编辑器
GO貌似还没有独自的IDE支持
可以考虑使用eclipse、vim等
在你下回来的go源包里面有个misc文件夹。里面有一些IDE的基础配置
包括了vim,notepad+。复制到你编辑器对应的地方即可。
另外自己是用的eclipse来进行编辑的,效果不错。
任意eclipse版本。打开帮助-安装新软件
键入这个
http://goclipse.googlecode.com/svn/trunk/goclipse-update-site/

全部勾上,注意绿色的地方可以取消钩,这样快一点,这个插件和其他的没有依赖关系。
安装完成之后。窗口-设置里面就可以看到GO的设置项了

填上GO的路径就可以开工啦~
注意:
这个扩展要求了工程的存放形式必须按规范来。

源码放在src里面,保存的时候会自动编译,如果报错
Executable source files must be in the ‘cmd’ folder
可以右键看看工程的设置是不是有问题

四、语法补全
go官方提供的放在源包里面的api文件夹。
但是没有和编辑器关联起来。
用的eclipse可以看到有个gocode设置的地方
gocode可以通过两个方式
第一是用go get github.com/nsf/gocode 安装
项目地址 https://github.com/nsf/gocode
第二是 其实我们的eclipse插件里面就带了!
他在你eclipse的文件夹的plugin里面。
\eclipse4.3_win64\plugins\com.googlecode.goclipse.gocode_0.7.6.v450\tools
比如我这里是这个路径。
进去后你就可以看到已经打包好的文件们。
不过这玩意儿不太稳定的说。
GO语言之并发与携程
[转]EMC中国研究院 颜开
简介
多核处理器越来越普及,那有没有一种简单的办法,能够让我们写的软件释放多核的威力?答案是:Yes。随着Golang, Erlang, Scale等为并发设计的程序语言的兴起,新的并发模式逐渐清晰。正如过程式编程和面向对象一样,一个好的编程模式需要有一个极其简洁的内核,还有在此之 上丰富的外延,可以解决现实世界中各种各样的问题。本文以GO语言为例,解释其中内核、外延。
并发模式之内核
这种并发模式的内核只需要协程和通道就够了。其中协程负责执行代码,通道负责在协程之间传递事件。
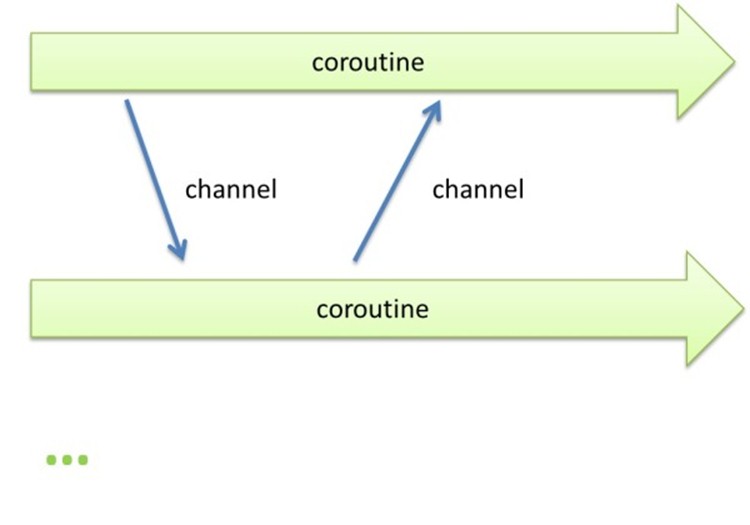
并发编程一直以来都是个非常困难的工作。要想编写一个良好的并发程序,我们不得不了解线程,锁,semaphore,barrier甚至CPU更新高速缓存的方式,而且他们个个都有怪脾气,处处是陷阱。笔者除非万不得以,决不会自己操作这些底层并发元素。一个简洁的并发模式不需要这些复杂的底层元素,只需协程和通道就够了。
协程是轻量级的线程。在过程式编程中,当调用一个过程的时候,需要等待其执行完才返回。而调用一个协程的时候,不需要等待其执行完,会立即返回。协程十分 轻量,Go语言可以在一个进程中执行有数以十万计的协程,依旧保持高性能。而对于普通的平台,一个进程有数千个线程,其CPU会忙于上下文切换,性能急剧 下降。随意创建线程可不是一个好主意,但是我们可以大量使用的协程。
通道是协程之间的数据传输通道。通道可以在众多的协程之间传递数据,具体可以值也可以是个引用。通道有两种使用方式。
· 协程可以试图向通道放入数据,如果通道满了,会挂起协程,直到通道可以为他放入数据为止。
· 协程可以试图向通道索取数据,如果通道没有数据,会挂起协程,直到通道返回数据为止。
如此,通道就可以在传递数据的同时,控制协程的运行。有点像事件驱动,也有点像阻塞队列。这两个概念非常的简单,各个语言平台都会有相应的实现。在Java和C上也各有库可以实现两者。

只要有协程和通道,就可以优雅的解决并发的问题。不必使用其他和并发有关的概念。那如何用这两把利刃解决各式各样的实际问题呢?
并发模式之外延
协程相较于线程,可以大量创建。打开这扇门,我们拓展出新的用法,可以做生成器,可以让函数返回”服务”,可以让循环并发执行,还能共享变量。但是出现新 的用法的同时,也带来了新的棘手问题,协程也会泄漏,不恰当的使用会影响性能。下面会逐一介绍各种用法和问题。演示的代码用GO语言写成,因为其简洁明 了,而且支持全部功能。
生成器
有的时候,我们需要有一个函数能不断生成数据。比方说这个函数可以读文件,读网络,生成自增长序列,生成随机数。这些行为的特点就是,函数的已知一些变量,如文件路径。然后不断调用,返回新的数据。
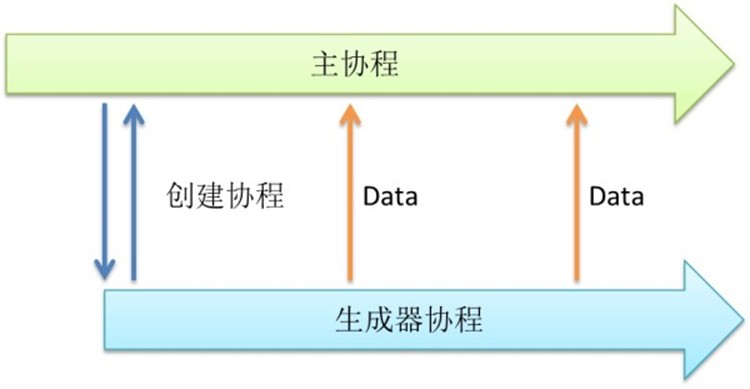
下面生成随机数为例,以让我们做一个会并发执行的随机数生成器。
非并发的做法是这样的:
// 函数rand_generator_1 ,返回 int
funcrand_generator_1() int {
return rand.Int()
}
上面是一个函数,返回一个int。假如rand.Int()这个函数调用需要很长时间等待,那该函数的调用者也会因此而挂起。所以我们可以创建一个协程,专门执行rand.Int()。
// 函数rand_generator_2,返回通道(Channel)
funcrand_generator_2() chan int {
// 创建通道
out := make(chan int)
// 创建协程
go func() {
for {
//向通道内写入数据,如果无人读取会等待
out <- rand.Int()
}
}()
return out
}
funcmain() {
// 生成随机数作为一个服务
rand_service_handler :=rand_generator_2()
// 从服务中读取随机数并打印
fmt.Printf(“%d\n”,<-rand_service_handler)
}
上面的这段函数就可以并发执行了rand.Int()。有一点值得注意到函数的返回可以理解为一个”服务”。但我们需要获取随机数据时候,可以随时向这个 服务取用,他已经为我们准备好了相应的数据,无需等待,随要随到。如果我们调用这个服务不是很频繁,一个协程足够满足我们的需求了。但如果我们需要大量访 问,怎么办?我们可以用下面介绍的多路复用技术,启动若干生成器,再将其整合成一个大的服务。
调用生成器,可以返回一个”服务”。可以用在持续获取数据的场合。用途很广泛,读取数据,生成ID,甚至定时器。这是一种非常简洁的思路,将程序并发化。
多路复用
多路复用是让一次处理多个队列的技术。Apache使用处理每个连接都需要一个进程,所以其并发性能不是很好。而Nginx使用多路复用的技术,让一 个进程处理多个连接,所以并发性能比较好。同样,在协程的场合,多路复用也是需要的,但又有所不同。多路复用可以将若干个相似的小服务整合成一个大服务。
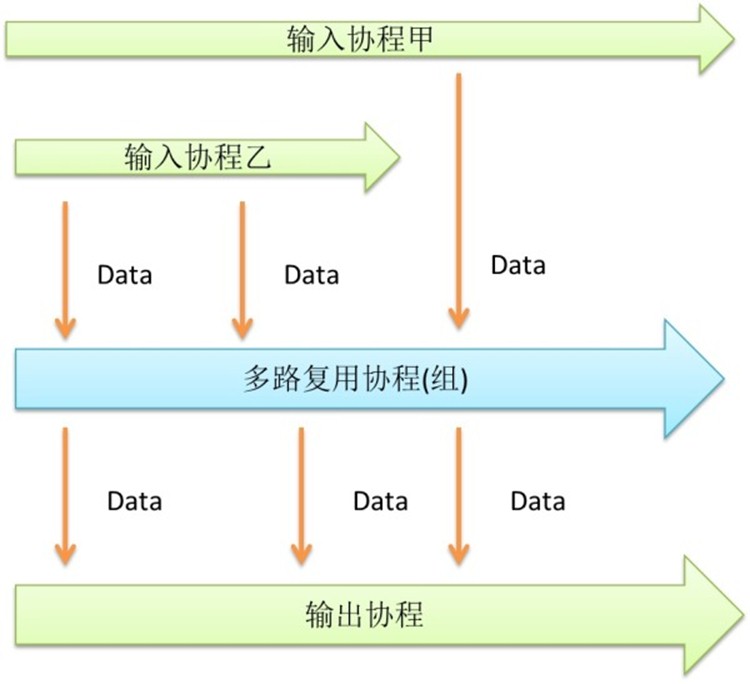
那么让我们用多路复用技术做一个更高并发的随机数生成器吧。
// 函数rand_generator_3 ,返回通道(Channel)
funcrand_generator_3() chan int {
// 创建两个随机数生成器服务
rand_generator_1 := rand_generator_2()
rand_generator_2 := rand_generator_2()
//创建通道
out := make(chan int)
//创建协程
go func() {
for {
//读取生成器1中的数据,整合
out <-<-rand_generator_1
}
}()
go func() {
for {
//读取生成器2中的数据,整合
out <-<-rand_generator_2
}
}()
return out
}
上面是使用了多路复用技术的高并发版的随机数生成器。通过整合两个随机数生成器,这个版本的能力是刚才的两倍。虽然协程可以大量创建,但是众多协程还是会 争抢输出的通道。Go语言提供了Select关键字来解决,各家也有各家窍门。加大输出通道的缓冲大小是个通用的解决方法。
多路复用技术可以用来整合多个通道。提升性能和操作的便捷。配合其他的模式使用有很大的威力。
Future技术
Future是一个很有用的技术,我们常常使用Future来操作线程。我们可以在使用线程的时候,可以创建一个线程,返回Future,之后可以通过它等待结果。 但是在协程环境下的Future可以更加彻底,输入参数同样可以是Future的。
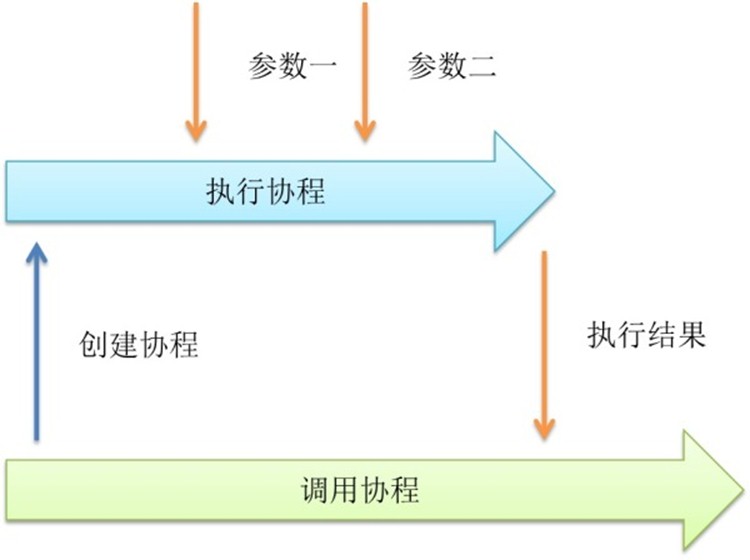
调用一个函数的时候,往往是参数已经准备好了。调用协程的时候也同样如此。但是如果我们将传入的参数设为通道,这样我们就可以在不准备好参数的情况下调用 函数。这样的设计可以提供很大的自由度和并发度。函数调用和函数参数准备这两个过程可以完全解耦。下面举一个用该技术访问数据库的例子。
//一个查询结构体
typequery struct {
//参数Channel
sql chan string
//结果Channel
result chan string
}
//执行Query
funcexecQuery(q query) {
//启动协程
go func() {
//获取输入
sql := <-q.sql
//访问数据库,输出结果通道
q.result <- “get” + sql
}()
}
funcmain() {
//初始化Query
q :=
query{make(chan string, 1),make(chan string, 1)}
//执行Query,注意执行的时候无需准备参数
execQuery(q)
//准备参数
q.sql <- “select * fromtable”
//获取结果
fmt.Println(<-q.result)
}
上面利用Future技术,不单让结果在Future获得,参数也是在Future获取。准备好参数后,自动执行。Future和生成器的区别在 于,Future返回一个结果,而生成器可以重复调用。还有一个值得注意的地方,就是将参数Channel和结果Channel定义在一个结构体里面作为 参数,而不是返回结果Channel。这样做可以增加聚合度,好处就是可以和多路复用技术结合起来使用。
Future技术可以和各个其他技术组合起来用。可以通过多路复用技术,监听多个结果Channel,当有结果后,自动返回。也可以和生成器组合使用,生 成器不断生产数据,Future技术逐个处理数据。Future技术自身还可以首尾相连,形成一个并发的pipe filter。这个pipe filter可以用于读写数据流,操作数据流。
Future是一个非常强大的技术手段。可以在调用的时候不关心数据是否准备好,返回值是否计算好的问题。让程序中的组件在准备好数据的时候自动跑起来。
并发循环
循环往往是性能上的热点。如果性能瓶颈出现在CPU上的话,那么九成可能性热点是在一个循环体内部。所以如果能让循环体并发执行,那么性能就会提高很多。
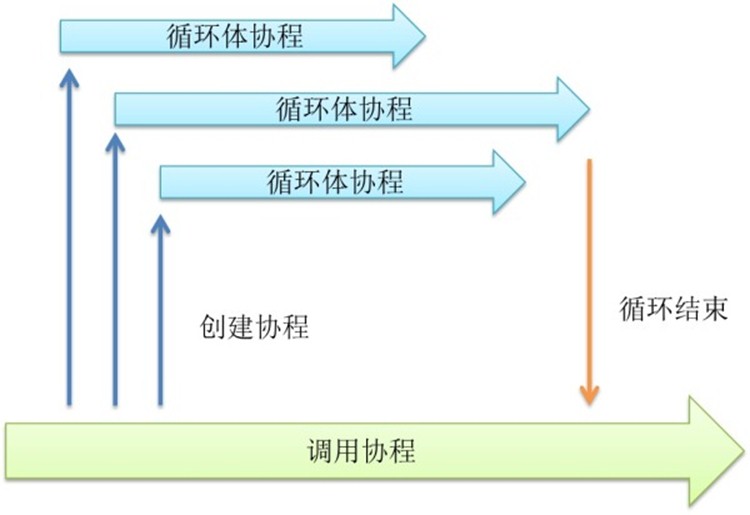
要并发循环很简单,只有在每个循环体内部启动协程。协程作为循环体可以并发执行。调用启动前设置一个计数器,每一个循环体执行完毕就在计数器上加一个元素,调用完成后通过监听计数器等待循环协程全部完成。
//建立计数器
sem :=make(chan int, N);
//FOR循环体
for i,xi:= range data {
//建立协程
go func (i int, xi float) {
doSomething(i,xi);
//计数
sem <- 0;
} (i, xi);
}
// 等待循环结束
for i := 0; i < N; ++i { <-sem }
上面是一个并发循环例子。通过计数器来等待循环全部完成。如果结合上面提到的Future技术的话,则不必等待。可以等到真正需要的结果的地方,再去检查数据是否完成。
通过并发循环可以提供性能,利用多核,解决CPU热点。正因为协程可以大量创建,才能在循环体中如此使用,如果是使用线程的话,就需要引入线程池之类的东西,防止创建过多线程,而协程则简单的多。
ChainFilter技术
前面提到了Future技术首尾相连,可以形成一个并发的pipe filter。这种方式可以做很多事情,如果每个Filter都由同一个函数组成,还可以有一种简单的办法把他们连起来。
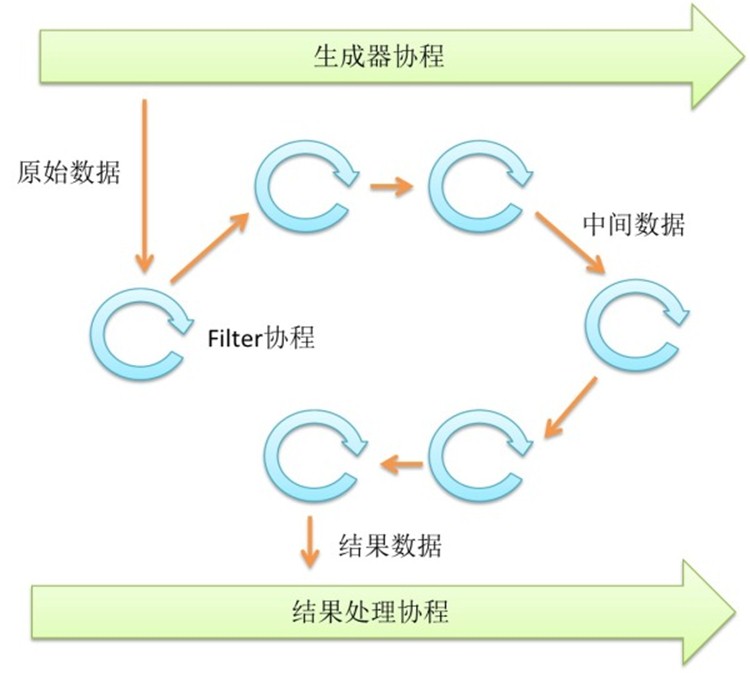
由于每个Filter协程都可以并发运行,这样的结构非常有利于多核环境。下面是一个例子,用这种模式来产生素数。
// Aconcurrent prime sieve
packagemain
// Sendthe sequence 2, 3, 4, … to channel ‘ch’.
funcGenerate(ch chan<- int) {
for i := 2; ; i++ {
ch<- i // Send ‘i’ to channel ‘ch’.
}
}
// Copythe values from channel ‘in’ to channel ‘out’,
//removing those divisible by ‘prime’.
funcFilter(in <-chan int, out chan<- int, prime int) {
for {
i := <-in // Receive valuefrom ‘in’.
if i%prime != 0 {
out <- i // Send’i’ to ‘out’.
}
}
}
// Theprime sieve: Daisy-chain Filter processes.
funcmain() {
ch := make(chan int) // Create a newchannel.
go Generate(ch) // Launch Generate goroutine.
for i := 0; i < 10; i++ {
prime := <-ch
print(prime, “\n”)
ch1 := make(chan int)
go Filter(ch, ch1, prime)
ch = ch1
}
}
上面的程序创建了10个Filter,每个分别过滤一个素数,所以可以输出前10个素数。
Chain-Filter通过简单的代码创建并发的过滤器链。这种办法还有一个好处,就是每个通道只有两个协程会访问,就不会有激烈的竞争,性能会比较好。
共享变量
协程之间的通信只能够通过通道。但是我们习惯于共享变量,而且很多时候使用共享变量能让代码更简洁。比如一个Server有两个状态开和关。其他仅仅希望获取或改变其状态,那又该如何做呢。可以将这个变量至于0通道中,并使用一个协程来维护。
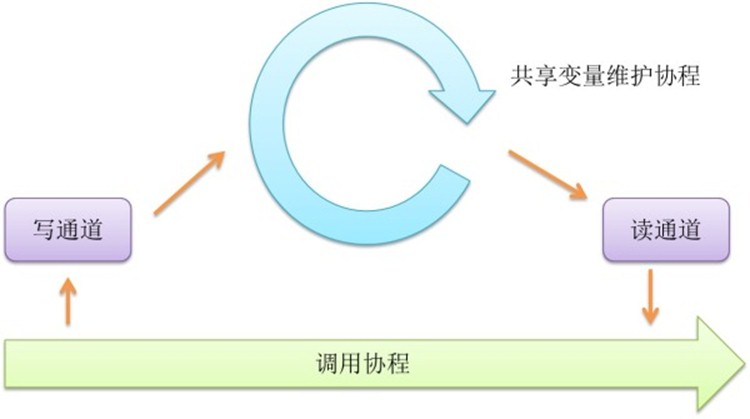
下面的例子描述如何用这个方式,实现一个共享变量。
//共享变量有一个读通道和一个写通道组成
typesharded_var struct {
reader chan int
writer chan int
}
//共享变量维护协程
funcsharded_var_whachdog(v sharded_var) {
go func() {
//初始值
var value int = 0
for {
//监听读写通道,完成服务
select {
case value =<-v.writer:
case v.reader <-value:
}
}
}()
}
funcmain() {
//初始化,并开始维护协程
v := sharded_var{make(chan int),make(chan int)}
sharded_var_whachdog(v)
//读取初始值
fmt.Println(<-v.reader)
//写入一个值
v.writer <- 1
//读取新写入的值
fmt.Println(<-v.reader)
}
这样,就可以在协程和通道的基础上实现一个协程安全的共享变量了。定义一个写通道,需要更新变量的时候,往里写新的值。再定义一个读通道,需要读的时候,从里面读。通过一个单独的协程来维护这两个通道。保证数据的一致性。
一般来说,协程之间不推荐使用共享变量来交互,但是按照这个办法,在一些场合,使用共享变量也是可取的。很多平台上有较为原生的共享变量支持,到底用那种 实现比较好,就见仁见智了。另外利用协程和通道,可以还实现各种常见的并发数据结构,如锁等等,就不一一赘述。
协程泄漏
协程和内存一样,是系统的资源。对于内存,有自动垃圾回收。但是对于协程,没有相应的回收机制。会不会若干年后,协程普及了,协程泄漏和内存泄漏一样成为 程序员永远的痛呢?一般而言,协程执行结束后就会销毁。协程也会占用内存,如果发生协程泄漏,影响和内存泄漏一样严重。轻则拖慢程序,重则压垮机器。
C和C++都是没有自动内存回收的程序设计语言,但只要有良好的编程习惯,就能解决规避问题。对于协程是一样的,只要有好习惯就可以了。
只有两种情况会导致协程无法结束。一种情况是协程想从一个通道读数据,但无人往这个通道写入数据,或许这个通道已经被遗忘了。还有一种情况是程想往一个通道写数据,可是由于无人监听这个通道,该协程将永远无法向下执行。下面分别讨论如何避免这两种情况。
对于协程想从一个通道读数据,但无人往这个通道写入数据这种情况。解决的办法很简单,加入超时机制。对于有不确定会不会返回的情况,必须加入超时,避免出 现永久等待。另外不一定要使用定时器才能终止协程。也可以对外暴露一个退出提醒通道。任何其他协程都可以通过该通道来提醒这个协程终止。
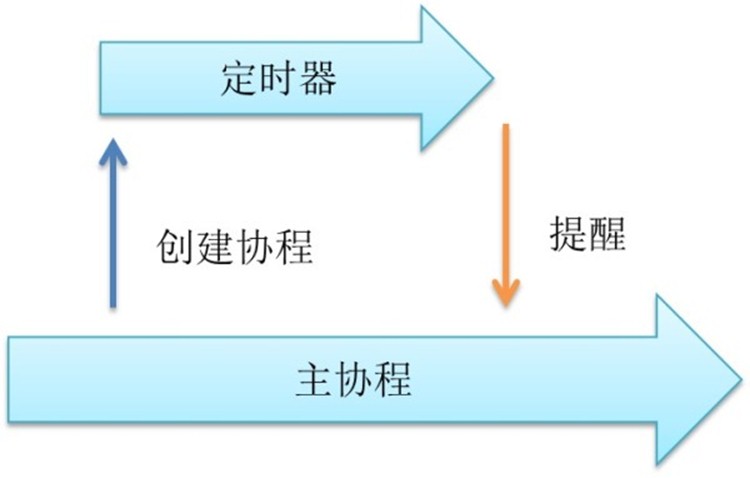
对于协程想往一个通道写数据,但通道阻塞无法写入这种情况。解决的办法也很简单,就是给通道加缓冲。但前提是这个通道只会接收到固定数目的写入。比方说, 已知一个通道最多只会接收N次数据,那么就将这个通道的缓冲设置为N。那么该通道将永远不会堵塞,协程自然也不会泄漏。也可以将其缓冲设置为无限,不过这 样就要承担内存泄漏的风险了。等协程执行完毕后,这部分通道内存将会失去引用,会被自动垃圾回收掉。
funcnever_leak(ch chan int) {
//初始化timeout,缓冲为1
timeout := make(chan bool, 1)
//启动timeout协程,由于缓存为1,不可能泄露
go func() {
time.Sleep(1 * time.Second)
timeout <- true
}()
//监听通道,由于设有超时,不可能泄露
select {
case <-ch:
// a read from ch hasoccurred
case <-timeout:
// the read from ch has timedout
}
}
上面是个避免泄漏例子。使用超时避免读堵塞,使用缓冲避免写堵塞。
和内存里面的对象一样,对于长期存在的协程,我们不用担心泄漏问题。一是长期存在,二是数量较少。要警惕的只有那些被临时创建的协程,这些协程数量大且生 命周期短,往往是在循环中创建的,要应用前面提到的办法,避免泄漏发生。协程也是把双刃剑,如果出问题,不但没能提高程序性能,反而会让程序崩溃。但就像 内存一样,同样有泄漏的风险,但越用越溜了。
并发模式之实现
在并发编程大行其道的今天,对协程和通道的支持成为各个平台比不可少的一部分。虽然各家有各家的叫法,但都能满足协程的基本要求—并发执行和可大量创建。笔者对他们的实现方式总结了一下。
下面列举一些已经支持协程的常见的语言和平台。
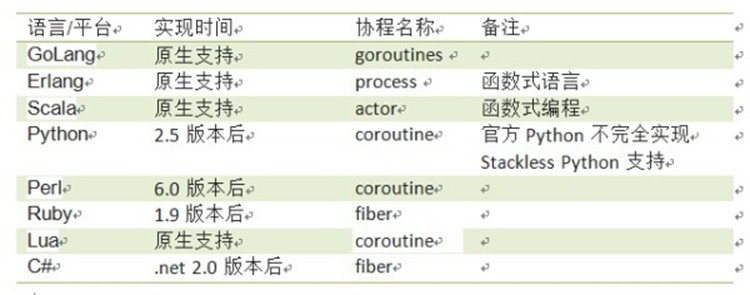
GoLang 和Scala作为最新的语言,一出生就有完善的基于协程并发功能。Erlang最为老资格的并发编程语言,返老还童。其他二线语言则几乎全部在新的版本中加入了协程。
令人惊奇的是C/C++和Java这三个世界上最主流的平台没有在对协程提供语言级别的原生支持。他们都背负着厚重的历史,无法改变,也无需改变。但他们还有其他的办法使用协程。
Java平台有很多方法实现协程:
· 修改虚拟机:对JVM打补丁来实现协程,这样的实现效果好,但是失去了跨平台的好处
· 修改字节码:在编译完成后增强字节码,或者使用新的JVM语言。稍稍增加了编译的难度。
· 使用JNI:在Jar包中使用JNI,这样易于使用,但是不能跨平台。
· 使用线程模拟协程:使协程重量级,完全依赖JVM的线程实现。
其中修改字节码的方式比较常见。因为这样的实现办法,可以平衡性能和移植性。最具代表性的JVM语言Scale就能很好的支持协程并发。流行的Java Actor模型类库akka也是用修改字节码的方式实现的协程。
对于C语言,协程和线程一样。可以使用各种各样的系统调用来实现。协程作为一个比较高级的概念,实现方式实在太多,就不讨论了。比较主流的实现有libpcl, coro,lthread等等。
对于C++,有Boost实现,还有一些其他开源库。还有一门名为μC++语言,在C++基础上提供了并发扩展。
可见这种编程模型在众多的语言平台中已经得到了广泛的支持,不再小众。如果想使用的话,随时可以加到自己的工具箱中。
结语
本文探讨了一个极其简洁的并发模型。在只有协程和通道这两个基本元件的情况下。可以提供丰富的功能,解决形形色色实际问题。而且这个模型已经被广泛的实 现,成为潮流。相信这种并发模型的功能远远不及此,一定也会有更多更简洁的用法出现。或许未来CPU核心数目将和人脑神经元数目一样多,到那个时候,我们 又要重新思考并发模型了。
from:http://qing.blog.sina.com.cn/2294942122/88ca09aa33002ele.html
python版网页抓取器railgun
实在受困于主机资源,跑个java几百M的内存就去了。
所以用python重新写了一份railgun。
比java版的更简洁,去掉了一些用不上的部分。包括抓取后的全文索引和数据库mapping部分。
现在它只是一个简单的抓取框架了,一个python的简单抓取网页的工具。
可以让用python抓取网页更加方便,轻松+愉快。
使用方式详见里面的有个现有所有功能的demo
项目主页:
https://github.com/princehaku/pyrailgun
下载地址:
https://pypi.python.org/packages/source/P/PyRailgun/
也可以从pipi安装
https://pypi.python.org/pypi/PyRailgun
简单的使用说明:
怎么使用? 首先你需要创建一个对应站点的规则文件 比如testsite.yaml
你的所有抓取过程,解析规则,都是在yaml文件里面定义的
- action: main
- name: “vc动漫”
- subaction:
- – action: fetcher
- url: http://www.verycd.com/base/cartoon/page${1,1}${0,9}
- subaction:
- – action: parser
- rule: .entry_cover_list li
- subaction:
- – action: shell
- group: default
- subaction:
- – {action: parser, rule: ‘.entry_cover .cover_img’, setField: img}
- – {action: parser, rule: ‘a’, pos: 0, attr: href, setField: src}
- – {action: parser, strip: ‘true’, rule: ‘.entry_cover .score’, setField: score}
- – {action: parser, rule: ‘.bio a’, setField: dest}
- – action: fetcher
- url: http://www.verycd.com${#src}
- subaction:
- – {action: parser,strip: ‘true’, rule: ‘#contents_more’, setField: description}
规则差不多就像你上面看到的这些,demo里面也有几个特殊的
接下来就可以在代码里面使用它了,把它作为一个任务加入到railgun
- from railgun import RailGun
- railgun = RailGun()
- railgun.setTask(file(“testsite.yaml”));
- railgun.fire();
- nodes = railgun.getShells(‘default’)
- print nodes
你就可以得到一个包含了所有解析后数据的节点列表。
[{img:xxx,src:xxx,score:xxx,dest:xxx,description:xxx},{img:xxx,src:xxx,score:xxx,dest:xxx,description:xxx}]
接下来怎么使用他么就是你随意的事情老!
安全的rm
一个不小心rm掉文件了吧?
后悔莫及了吧!
把这段代码加入你的home目录的.bashrc或者.zshrc就可以了
- ### by 3haku.net
- function saferm() {
- ops_array=($*)
- if [[ –z $1 ]] ;then
- echo ‘Missing Args’
- return
- fi
- J=0
- offset=0
- # for zsh
- if [[ –z ${ops_array[0]} ]] ; then
- offset=1
- fi
- while [[ $J –lt $# ]] ; do
- p_posi=$(($J + $offset))
- dst_name=${ops_array[$p_posi]}
- if [[ `echo ${dst_name} | cut -c 1` == ‘-‘ ]] ; then
- continue
- fi
- # garbage collect
- now=$(date +%s)
- for s in $(ls —indicator–style=none $HOME/.trash/) ;do
- dir_name=${s//_/-}
- dir_time=$(date +%s –d $dir_name)
- # if big than one month then delete
- if [[ 0 –eq dir_time || $(($now – $dir_time)) –gt 2592000 ]] ;then
- echo “Trash “ $dir_name ” has Gone “
- /bin/rm $HOME/.trash/$dir_name –rf
- fi
- done
- # add new folder
- prefix=$(date +%Y_%m_%d)
- hour=$(date +%H)
- mkdir –p $HOME/.trash/$prefix/$hour
- echo “Trashing “ $dst_name
- mv ./$dst_name $HOME/.trash/$prefix/$hour
- J=$(($J+1))
- done
- }
- alias rm=saferm
工作原理:
在你的home目录会创建一个.trash文件夹
里面会按照删除时间 年-月-日/小时/ 进行归档已删除的文件
然后会删除一个月以前的文件夹
就是这样!
复制百度文库内容chrome插件
百度也太恶心了,又把它自己的文库权重提高了。
进去又是用flash来加载的,没法复制,文档下载又要积分。
于是做了一个插件,作用是让百度文库内的内容可以直接进行复制粘贴。
用之前效果

用了插件后效果如下。

不过带来两个问题,一个是排版没了。二个是下载按钮不能点击了。
当然其实不用插件也可以,把wenku.baidu.com该成wk.baidu.com即可
聊胜于无,呵呵,原理是修改request的referer。
源码 https://github.com/princehaku/wenkupaster
下载 [download id=”44″]
MVC in php — 控制器(Controller)
控制器,有的地方又称之为Action。
它是MVC中的C,控制视图展现
它会担负很多任务。要接受请求,要选择M处理,最后选择V来显示。
一般在php中大多数情况下他都作为业务的处理层了。
比如对传入参数进行处理,对显示元素进行组装。
它的实现一般也两类
通过对象的映射或者是通过文件包含的形式
最简单当然就是通过文件包含的形式。
比如访问index.php/aa/bb/cc
可以让程序加载aa目录下的bb文件
然后之后的作为参数注入,这个过程在路由模块中实现
另外的一种就是通过类的方式
一般说来以类方式实现的控制器大致会长成这样
<?php
class IndexController extends CController{
public function sae() {
echo 'Hello';
}
}
现在有一个请求index.php/index/sae
怎样路由到它上面呢?
方法也是多种多样的~
首先我可以从url上得到参数
$action = 'index';
$method = 'sae';
然后通过$ac = new $action();
可以得到一个新的IndexController实例
然后再调用$ac->$method();
就阔以了。
另外的方式就是通过反射来实现。
以上两种方式都会出现一个问题,如果我即将包含的这个文件IndexController.php中包含错误
或者是在sae() (执行过程中) 出现了错误被终止。我怎样去捕获它呢?
在php的oop中,exception的处理并没有java那样严格。不会强制要求throws Exception
比如以下的例子
<?php
class a {
public function expt() {
throw new Exception(‘wa!’);
}
}
class c {
public function combinea() {
$a = new a();
$a->expt();
}
}
$c = new c();
$c->combinea();
它会抛出一个Fatal error: Uncaught exception 'Exception'
但是在php5.2的某些版本,他什么都不会输出,而且你也不能用try catch来捕获$c->combinea()抛出的异常。
最怕的不是出错,而是出了错什么都没有记录。增加了你debug的难度。
然后是另外一个问题~
如果我想要访问的地址是
index.php/index/list
<?php
class IndexController extends CController{
public function list() {
echo 'Hello';
}
}
注意! list这个词是php的预留词,所以这个文件语法有问题,包含的时候就会报错。
一些框架的解决方案是方法前统一加个词 比如action
控制器大致是这样的
<?php
class IndexController extends CController{
public function actionlist() {
echo 'Hello';
}
}
Controller也会需要参数的获取,模型载入,库载入等等工作。
所以框架对这层进行封装,这些工作会在基类CController上实现。
这也是为什么90%的框架都需要让你继承它的基类。
比如获取参数,涉及到安全性,在框架层面就可以容易封装。
pafetion1.5版本发布
pafetion从2010年开始到现在快两年了。
上次1.4发布也是半年前了,居然也一直能用,稳定性由于移动的问题还算一般。
但是上上周开始有很多同学反馈不能发送消息了。
周末看了下,发现登陆的验证码现在会默认出现了。
没法跳过,所以这样的接口调用方式也就失败了。
然后最近按照http://blog.quanhz.com/的建议,跳过了登陆验证码。
然后给发送他人也加上了csrfToken,暂时又能用了。
调用方式都没有变化,参见【1.4版本】
下载地址
[download id=”43″]
2012年8月2号 不能使用
MVC in php — 路由(Router)
前面提到了控制器(C)和视图(V)
依据我们前面介绍的方式,主入口是index.php
不是通过对物理文件的映射来访问,而通过用户输入的URL来实现访问,依据用户输入的url指定到对应的控制器上。
这个部分就叫路由器(Router),它的存在目的就是实现单一入口
一个超级简陋的的url分发器如下
include $ROOT . "/action/" . $_GET[‘action’] . ".inc.php";
没错~ 这一句话也可以看做是一个router。它实现了单一入口
但是它存在什么问题呢?
第一,它不安全
如果我传入index.php?action=../../../../../../home/bzw/1
我的1.php将被包含在你的项目中运行,这个是一个本地文件包含漏洞【http://www.51cto.com/html/2005/1128/12370.htm】
第二,参数受限
一般用这种方式只能route到单个文件,不能针对类和类的方法进行映射
所以,一般采用这种方式实现的比较少,大多通过url mapping映射到类上
首先,我们来看看java的servlet实现方式
<servlet–mapping>
<servlet–name>dispatcher</servlet-name>
<url–pattern>*.do</url-pattern>
</servlet-mapping>
它把所有的*.do映射到servlet名称为dispatcher的上面,然后再由这个dispatcher通过反射,动态代理等方式映射到响应的控制器上。
在php中,一般采用有三种方式进行URL映射
第一种,也是比较容易接受的就是上面的通过url参数进行映射的方式,不过呢,一般是两个参数,分别代表控制器类和方法
比如index.php?c=index&m=index
映射到的是index控制器的index方法
第二种,是通过url-rewrite的方式,这样的好处是可以实现对非php结尾的其他后缀进行映射,当然通过rewrite也可以实现第一种方式,不过纯使用rewrite的也比较常见
一般需要配置apache或者nginx的rewrite规则
<IfModule mod_rewrite.c> RewriteEngine On RewriteBase / RewriteRule ^index\.php$ - [L] RewriteCond %{REQUEST_FILENAME} !-f RewriteCond %{REQUEST_FILENAME} !-d RewriteRule . /index.php [L] </IfModule>
通过这种方式可以把所有请求转发到index.php上,我们常用的wordpress就是这样的方式。然后程式再通过QUERY_STRING进行解析,映射和转发到响应的控制器上。
第三种,就是通过pathinfo的方式,所谓的pathinfo,就是形如这样的url xxx.com/index.php/c/index/aa/cc,apache在处理这个url的时候会把index.php后面的部分输入到环境变量$_SERVER[‘PATH_INFO’],它等于/c/index/aa/cc
然后我们的路由器再通过解析这个串进行分析就可以了,后面的部分放入到参数什么地方的,就依据各个框架不同而不同了。很多框架都喜好使用这种方式,但是这种方式缺有很多先天性的因素。
我知道的有两个,第一个是如果你的php工作在cgi或者fastcgi模式下,默认是没有传入PATH_INFO的,环境变量里面也没有这个值,需要对服务器进行配置,而且要注意php的配置里面有个cgi.fix_pathinfo是不是开启了,如果开启了会导致fastcgi的一个解析漏洞【http://www.80sec.com/nginx-securit.html】,
另外一个就是比如你的页面url是xxx.com/index.php/c/index/aa/cc 请小心图片,js目录的位置,有部分浏览器会认为你的当前路径在xxx.com/index.php/c/index/aa/下面,如果你的图片是a.jpg。那么它会去查找xxx.com/index.php/c/index/aa/a.jpg,导致图片和其他资源加载失败。
当然,大多数框架三者都是同时支持的。但是在路由过程中为什么要用类而不用文件来表示控制器呢?之后继续分解~
MVC in php — 框架的成型
一个框架是怎么成型的呢?为什么又要用MVC呢?
传统的php三层架构大致是页面显示,业务逻辑,数据库。

php联通后端数据源(数据库或者其他)然后经过业务逻辑渲染成html给用户(浏览器)
这一做法无可厚非,也是传统CRUD的核心,尽可能将他们拆开,优化,层次分离,便是一个框架需要做到的事情。
还拆?对
最最开始的时候,很多刚入门的程序员都比较钟爱传统的PHP嵌入式开发。
比如
将业务逻辑和前端展示放在一个页面输出,比如上图的index.php,但是文件随着业务逻辑的增长变得越来越大。代码也无法复用,阅读代码也变得异常的复杂。
比如以下这个文件[download id=”42″]
于是乎,聪明的程序员们决定抽出一些公共的函数,公共的配置,放在外面,供大家使用。

目录结构中多了几个文件,showad.php也变小了。但是逻辑依然和视图混合在一起。
但是问题又来了,项目中url越来越多,造成根目录下堆的文件也越来越多,

而且还有一些比如showad.php和showad_admin.php 他们取数据的过程是一致的,只是显示的页面上多了一个括号。本来可以写里面的,但是不知道谁怕改到别的童鞋修改的东西,就又添加了一个新文件。之后修改取得的数据的时候又得两个文件一起修改。来源一致但是显示不一致的问题没有得到解决。
于是大家觉得应该把视图和逻辑分开,把数据获取的工作全分离出来,然后目录结构优化成这样。

统一都从index.php引入,然后通过参数include配置文件,再include app目录对应响应的文件,最后再include view中的展示用的php。
恩恩~,它看起来有点那么个意思了,单一入口,app层控制view显示。module隐含在app里面,其实现在严格的说是没有module层的
接下来就详细介绍下他们的内涵